Entendendo o Presto
- JP
- 6 de jul. de 2021
- 3 min de leitura
O Presto é uma ferramenta bem conhecido no mundo Big Data, especificamente na área de Engenharia de dados. O Presto funciona como uma SQL Engine para análise de grandes volumes de dados distribuídos e heterogêneos. É um conceito um pouco subjetivo que vamos entender mais a frente.
Presto não substitui MySQL, Oracle, SQL Server e etc, muitas pessoas se confundem com esta ideia. O Presto é um contexto composto por uma engine robusta que possibilita processar um input no padrão ANSI-SQL em que possibilitará um resultado final ao consumidor.
Hoje no mercado temos algumas ferramentas/recursos baseados no Presto. Um deles é o conhecido AWS Athena. O Athena é um recurso que permite executar consultas interativas visando análise de dados. Entender o funcionamento do Athena, vai nos ajudar a entender também o funcionamento do Presto.
No Athena, um Datasource é dividido por um catalogo de dados externo ou um connector, ou seja, onde os dados estão alocados (Por ser um contexto da AWS, os times escolhem algum bucket do S3). E por fim, um com catalogo de metadados, mais uma vez, naturalmente utiliza-se o Glue, mas também é possível o Apache Hive.

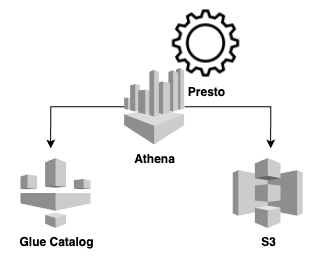
Contexto Athena x Presto
O que descrevemos anteriormente sobre a um Datasource no Athena é basicamente o contexto do Presto. O Presto é composto por diversos componentes que possibilitam processar uma entrada criando um processo de Query gerenciado por um componente que coordena todo o fluxo, chamado de Coordinator. Este Coordinator tem um papel em gerenciar os nós workers que trabalham em conjunto para entregar o resultado final ao cliente.
Da mesma forma que o Athena funciona, o Presto também possui suporte para diferentes catálogos de dados, incluindo o S3 e entre outros. Possui também uma lista extensa de catalogo de metadados e conectores.
Uma outra forma de entender o funcionamento e a sua finalidade, seria o seguinte cenário:
Imagine um cenário em que é necessário executar uma análise em cima de dados representados por uma grande quantidade de arquivos semi-estruturados. Para uma melhor análise, será utilizado o padrão ANSI-SQL para uma análise mais precisa. Para este contexto, poderíamos adotar o Presto para conectar aos dados, organizar os dados em um catalogo e tabelas e por fim, criar um ecossistema que possibilita analisar os dados.
Dentro deste contexto, o usuário poderia executar análises utilizando SQL baseadas nos arquivos em um repositório único, neste caso, um catálogo de dados mais transparente e possibilitando trabalhar com dados heterogêneos.
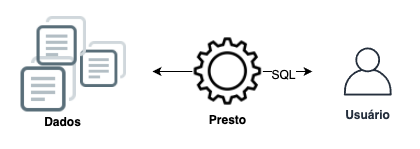

Entendendo melhor o funcionamento do Presto
Aqui vamos descrever os principais componentes do Presto, recomendo a leitura da sua documentação original.


Overview do contexto Presto
1. Coordinator
O Coordinator é o principal servidor e é o responsável por fazer os parses dos statements, queries, retornar o resultado final para o cliente e por gerenciar os workers. O Coordinator é o core de cada instalação, ou seja, uma peça chave para o funcionamento. A comunicação entre o Coordinator e os nós workers são através de API REST.
2. Workers
Os Workers são os nós responsáveis por executar as tasks e processar os dados estimulados pelo Coordinator. As comunicações entre os Workers e o Coordinator são feitas através de API REST.
3. Connector
O Connector é uma forma de adaptar Presto a um Datasource. É possível utilizar um Connector para ser utilizado junto ao Hive, MySQL, Redshift e entre vários outros. Resumidamente, o Connector funciona como um driver para um banco de dados.
4. Query Execution Model
Presto executa SQL statements que são convertidos em Queries que por fim, são executados através de clusters distribuídos e gerenciados pelo coordinator e workers.
5. Statement
Uma Statement é basicamente um texto SQL. Presto trabalha com statements seguindo os padrões ANSI-SQL, ou seja, possui expressões, cláusulas e etc.
É interessante não confundir uma Statement com Query, existe uma diferença na qual falaremos no próximo tópico.
6. Query
A Query é um processo criado a partir de uma Statement, ou seja, uma Statement é passada ao Presto e em seguida convertida para uma Query. A Query é um conjunto de fatores executados através de estágios interconectados e gerenciados pelos Workers.
Perceba que existe uma diferença entre Statement (Texto SQL) e Query. A Query é um processo criado através de uma Statement envolvendo alguns componentes. Já a Statement é a representação textual de um script SQL que segue o padrão ANSI-SQL que será passado e processado pelo Presto para um resultado final.
Para maiores informações sobre o Presto, recomendo bastante a leitura da doc
Este foi um post foi um pouco mais simples onde a ideia foi fazer um overview sobre o contexto do Presto, espero ter ajudado.
Até mais.
Comments